파이썬으로 안랩블로그 게시글 크롤링
Python을 사용하여 안랩블로그에서 게시글을 크롤링하는 예제 코드입니다.
아래 코드는 `requests` 모듈을 사용하여 안랩블로그 검색 페이지에 접속하고, `BeautifulSoup` 모듈을 사용하여 HTML을 파싱합니다. 그리고 검색 결과 중에서 제목과 링크를 추출하여 출력합니다.
# 안랩블로그 웹페이지 URL
url = "https://asec.ahnlab.com/ko/category/malware-ko/" 에 게시글 글을 크롤링해볼께요.
해당 URL에서 파싱하는 부분
# 웹페이지 요청 및 HTML 파싱
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
파싱된 soup에서 url, 제목, 시간순 정렬하는 코드는 아래와 같습니다.
# 각 게시물 블록을 순회하며 정보 추출
for post_block in soup.select('div.post-block-wrapper-latest'):
try:
# 게시 시간 추출 및 변환
stime = post_block.select_one('li.slider-meta-date').text.strip()
# '7월 29 2024'를 datetime 객체로 변환
stime_dt = datetime.strptime(stime, '%m월 %d %Y')
# '%Y-%m-%d %H:%M:%S' 형식으로 변환
stime_formatted = stime_dt.strftime('%Y-%m-%d %H:%M:%S')
# URL 및 제목 추출
title_tag = post_block.select_one('h3.post-title a')
title = title_tag.text.strip()
post_url = title_tag['href']
# 요약 추출
summary = post_block.select_one('div.post-excerpt-box p').text.strip()
# 추출한 정보를 딕셔너리로 저장
posts.append({
'stime': stime_formatted,
'title': title,
'url': post_url,
'summary': summary
})
except AttributeError:
# 특정 요소가 없는 경우 무시하고 계속 진행
continue
# 시간순으로 정렬
posts_sorted = sorted(posts, key=lambda x: x['stime'])
위와 같은 코드를 모은 전체 코드는 아래와 같습니다.
import requests
from bs4 import BeautifulSoup
from datetime import datetime
def ahnlab_craw():
# 웹페이지 URL
url = "https://asec.ahnlab.com/ko/category/malware-ko/"
# 웹페이지 요청 및 HTML 파싱
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 게시물 정보를 저장할 리스트
posts = []
# 각 게시물 블록을 순회하며 정보 추출
for post_block in soup.select('div.post-block-wrapper-latest'):
try:
# 게시 시간 추출 및 변환
stime = post_block.select_one('li.slider-meta-date').text.strip()
# '7월 29 2024'를 datetime 객체로 변환
stime_dt = datetime.strptime(stime, '%m월 %d %Y')
# '%Y-%m-%d %H:%M:%S' 형식으로 변환
stime_formatted = stime_dt.strftime('%Y-%m-%d %H:%M:%S')
# URL 및 제목 추출
title_tag = post_block.select_one('h3.post-title a')
title = title_tag.text.strip()
post_url = title_tag['href']
# 요약 추출
summary = post_block.select_one('div.post-excerpt-box p').text.strip()
# 추출한 정보를 딕셔너리로 저장
posts.append({
'stime': stime_formatted,
'title': title,
'url': post_url,
'summary': summary
})
except AttributeError:
# 특정 요소가 없는 경우 무시하고 계속 진행
continue
# 시간순으로 정렬
posts_sorted = sorted(posts, key=lambda x: x['stime'])
# 결과 출력
for post in posts_sorted:
print(f"Time: {post['stime']}")
print(f"Title: {post['title']}")
print(f"URL: {post['url']}")
print(f"Summary: {post['summary']}")
print('-' * 40)
if __name__ == '__main__':
ahnlab_craw()
실행결과
아래와 같이 실행해서 안랩블로그의 게시글을 가져올 수 있습니다.
```shell
python v3_crawling.py
```
이렇게 실행했을때 아래와 같이 크롤링이 잘 되는것을 확인할 수 있습니다.
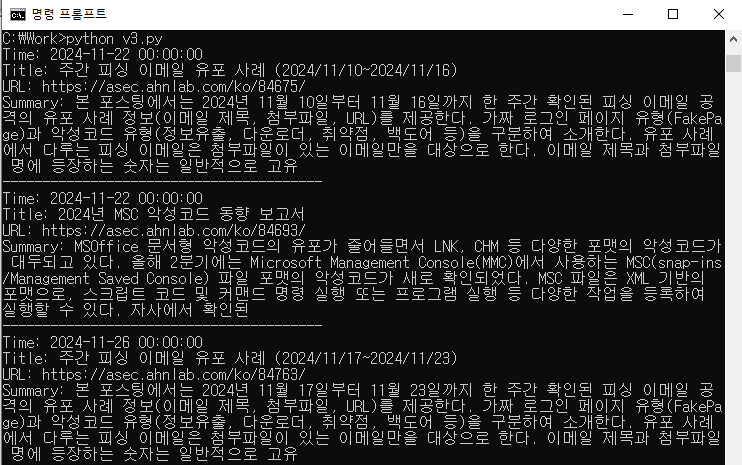
위 코드를 조금 수정해서 url을 받아들이는 방식으로 변경하면 안랩블로그의 다른 게시글도 크롤링이 가능합니다.
악성코드 게시글과 취약점 게시글을 크롤링 해보겠습니다.
import requests
from bs4 import BeautifulSoup
from datetime import datetime
def ahnlab_craw(url):
# 웹페이지 URL
# 웹페이지 요청 및 HTML 파싱
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 게시물 정보를 저장할 리스트
posts = []
# 각 게시물 블록을 순회하며 정보 추출
for post_block in soup.select('div.post-block-wrapper-latest'):
try:
# 게시 시간 추출 및 변환
stime = post_block.select_one('li.slider-meta-date').text.strip()
# '7월 29 2024'를 datetime 객체로 변환
stime_dt = datetime.strptime(stime, '%m월 %d %Y')
# '%Y-%m-%d %H:%M:%S' 형식으로 변환
stime_formatted = stime_dt.strftime('%Y-%m-%d %H:%M:%S')
# URL 및 제목 추출
title_tag = post_block.select_one('h3.post-title a')
title = title_tag.text.strip()
post_url = title_tag['href']
# 요약 추출
summary = post_block.select_one('div.post-excerpt-box p').text.strip()
# 추출한 정보를 딕셔너리로 저장
posts.append({
'stime': stime_formatted,
'title': title,
'url': post_url,
'summary': summary
})
except AttributeError:
# 특정 요소가 없는 경우 무시하고 계속 진행
continue
# 시간순으로 정렬
posts_sorted = sorted(posts, key=lambda x: x['stime'])
# 결과 출력
for post in posts_sorted:
print(f"Time: {post['stime']}")
print(f"Title: {post['title']}")
print(f"URL: {post['url']}")
print(f"Summary: {post['summary']}")
print('-' * 40)
if __name__ == '__main__':
# 안랩블로그(악성코드) 크롤링
url = "https://asec.ahnlab.com/ko/category/malware-ko/"
ahnlab_craw(url)
# 안랩블로그(취약점) 크롤링
url = 'https://asec.ahnlab.com/ko/category/vulnerability-ko/'
ahnlab_craw(url)'공학속으로 > python' 카테고리의 다른 글
| [python] 날씨 api를 사용하여 날씨, 습도 구하기 (1) | 2024.12.09 |
|---|---|
| [Python] 네이버API를 사용한 뉴스 검색 크롤링하기 (5) | 2024.09.20 |
| [Python] URL 목록 파일 이용한 파일 다운로드 (0) | 2024.07.16 |
| [파이썬] 관리자 모드로 외부 프로그램 실행하기 GUI (1) | 2023.12.16 |
| [파이썬] 파일 복사 GUI 형태로 만들기 (1) | 2023.12.16 |

댓글